Добавлено: Пт Мар 06, 2020 3:53 pm Заголовок сообщения:
Как я уже писал участники курса "Математика для полиграфолога" могут получить (бесплатно) последнюю версию программы, что естественно, так как они наиболее мотивированые лица в применении математических методов к оценке полиграмм и построения выводов по данным.
Остальным полиграфологам предлагаю проголосовать за развите проекта рублём. Т.е. если вы считаете проект полезным для инстументальной детекции лжи - можете сделать взнос на его развитие. Сумма взноса любая (хоть один рубль). Мне важно знать действительно ли российские полиграфологи заинтересованы в развитии прикладных математических методов, как некоторые писали мне в личной переписке. Или не очень.
Делая взнос можно оставить комментарий для меня, можно оставить свой email, если желаете получить полнофункциональную, последнюю версию программы. Я свяжусь с вами и скоипилирую индивидуальную копию программы.
Добавлено: Вт Мар 10, 2020 10:12 am Заголовок сообщения:
В статистике принято (что является обязательным) при оценке какого - либо параметра распределения вычислять доверительный интервал для оцениваемого параметра генеральной совокупности. Доверительный интервал - это такой интервал в котором с заранее выбранной вероятностью (доверительной), как правило это 95% (90%), находится истинное значение оцениваемого параметра.
Сокол вычисляет на выборке - ФОП, наблюдаемое значение которой является оценкой значения мат. ожидания (среднего) ФОП генеральной совокупности. Например, в условиях справедливости нулевой гипотезы мат. ожидание ФОП равно нулю.
В параметрической статистике доверительный интервал вычисляется исходя из знания распределения генеральной совокупности. В интсрументальной детекции лжи со знанием распределений большие проблемы. Но в непараметрической статистике существует специальная бутстреп - техника для оценки доверительных интервалов. С учётом вычислительной мощности современных компьютеров такие оценки являются достаточно точными.
Включил в Сокол бутстреп t - критерий для вычисления доверителного интервала. Необходимо сказать, что с помощью доверительного интервала можно проверять нулевую гипотезу. В случае ФОП, если ноль не попадает в доверительный интервал, то это является достаточным основанием, чтобы отказаться от нулевой гепотезы. Напомню, что принятие нулевой гипотезы в случае инструментальной детекции лжи - это так называемая "неопределённость".
На горизонте Сокола анализ полиграммы с помощью методов Бонферрони, Данна - Шидака и Холма.
Потихонечку Сокол превращается в "статистический непараметрический комбайн" для анализа полиграмм. Может возникнуть вопрос: Зачем столько тестов и критериев? Можно ответить: Чтобы было . Или задать встречный вопрос: А зачем полиграфологу проводить с опрашиваемым несколько тестов, если можно только один какой - нибудь?
И вообще при наличии многих возможностей "во всём теле какая - то гибкость образуется" _________________ http://skl-ol.ru https://t.me/skl_ol
Зарегистрирован: 11.11.2011 Сообщения: 1413 Откуда: г. Липецк
Добавлено: Чт Мар 12, 2020 8:55 am Заголовок сообщения:
Коллеги, просвещённые в высшей математике, поясните пожалуйста чем реально, чисто практически друг от друга отличаются поправка Бонферони и поправка Шидака применительно к практике полиграфолога.
Добавлено: Чт Мар 12, 2020 4:00 pm Заголовок сообщения:
vladkazackoff
Не знаю сможет ли кто - то из коллег ответить на ваш вопрос чисто из практических соображений. Для этого надо посмотреть, как они работают на практике хотя бы на нескольких десятках полиграмм. А вот исходя из теории можно объяснить в чём их смысл и на качественном уровне что - то предсказать (а количественно оценить практически).
Это примерно, как с тестом знаков. Из теории известно, что он использует минимальное количество информации об элементах выборки. И поэтому в сравнении с ранговыми тестами и тем более перестановочными он должен работать хуже. Чтобы убедиться в этом и понять насколько я включил этот тест в Сокол НТФП. И теперь с практической точки зрения могу сказать, что на характерных выборках инструментальной детекции лжи его мощность недостаточна для целей полиграфологов. Мощность теста растёт с увеличением объёма выборки. Это одна из причин (на практике убедиться в этом и посмотреть количественно) по которой я включил в программу генерацию дополнительных пар сравнения методом Монте - Карло. Мощность теста знаков растёт и примерно при десяти пар сравнения её можно назвать удовлетворительной (предварительная оценка)
Но значит ли что критерий знаков бесполезен для инструментальной детекции лжи? Я бы не был в этом категоричен. Если критерий знаков показывает достаточно маленький достигаемый уровень значимости на полиграмме, то это является большим плюсом в её оценке и в подтверждении результатов других тестов. В каких - то особых случаях, когда возникнет необходимость для обоснования точности выводов, эта возможность может пригодиться. Не знаю конечно в современных российских реалиях, возможно ли появление подобных необходимостей, но тем не менее надеюсь и уповаю , что здравый смысл, научная обоснованность и коммерческая необходимость переплетутся и получат тесную связь. Наверное, я идеалист .
Может ли быть так что статистические критерии: знаков, Вилкоксона, перестановочный, - дадут противоположные результаты в смысле альтернативных гипотез? При высоком достигаемом уровне значимости возможно, но в этом случае альтернативная гипотеза не будет важна, так как она всё равно не будет принята. А если тесты имеют низкий достигаемый уровень значимостей, то я ни разу ещё не наблюдал противоречий в альтернативных гипотезах и не знаю теоретических предпосылок к этому.
Надо добавить, что если один тест принимает альтернативную гипотезу, а другой остаётся на позиции нулевой, то это нельзя рассматривать как противоречащие друг другу результаты. Принятие нулевой гипотезы, если в её пользу нет сильных доводов из предметной области, не означает отрицание альтернативной. Такой результат говорит лишь о том, что качество данных таково, что тест не может отвергнуть нулевую гипотезу. Причиной тому может быть малость объёма выборки, низкая мощность теста. В таком случае надо просто ориентироваться на тест с большей мощностью. По аналоги с полиграфный тестами - допустим провели два теста и один дал неопределённость, а другой уверенно свидетельствует, допустим, о причастности. Результаты тестов не противоречат друг другу. В первом случае зафиксированные реакции таковы, что нет возможности убедительно ответить на поставленный вопрос, а результаты второго позволяют сделать вывод в общем.
Кроме того м статистике есть техники позволяющие учитывать достигаемый уровень нескольких тестов и буквально на основе их уровней значимости выводить интегрированный.
Добавлено: Чт Мар 12, 2020 4:54 pm Заголовок сообщения:
Возвращаясь к сути вопроса, надо отметит, что в случае оценки полигамы сравниваемые пары сравниваются по трём, а возможно и по четырём зарегистрированным показателям. Т.е. выборки сравниваются по нескольким показателям, а такая задача может быть решена либо с помощью многомерных методов, либо применением критериев для каждого показателя в отдельности, но при этом корректируя уровни значимости с учётом множественности сравнения. Я думаю, что какой - ни будь исследователь из другой области именно так бы и решал задачу оценки полиграмм, если б не был предварительно ознакомлен с эмпирически полученной и обоснованной балльной оценкой.
Т.е. он решал бы задачу о том различаются ли реакции опрашиваемого на вопросы статистически значимо по каждому из каналов. Например, применив вышеуказанные методы, он мог бы сказать, что реакции статистически значимо различаются по всем измеряемым переменным. И его задача была бы решена. В тоже время полиграфолог на той же полиграмме мог бы получить по Дых (-5) КГР (+10) Кардио (-5), и в сумме 0 баллов. И сказал бы что вывод неопределённый. Никаких бы противоречий между этими результатами не было бы. По каждому каналу в отдельности реакции на сравниваемые вопросы действительно различаются значимо, но полиграфолог оценивает их в совокупности. Он суммирует результат по каждому каналу, исходя из предпосылки, что они одинаково важны. А вот если б результат был +5, +10, +5, то между исследователем и полиграфологм возник бы полный консенсус и взаимопонимание)
Полиграфолог сначала преобразует. трансформирует наблюдаемые данные (например, находит отношение амплитуд), далее переводит их в баллы и находит их сумму по каждому каналу. Эта практика, мы верим, имеет эмпирическое подтверждение в виде достигаемой точности, чувствительности и специфичности тестов, о чём нам сообщают зарубежные коллеги. Такая ситуация, возможно, характерна для инструментальной детекции лжи. Если есть, что - либо подобное в других областях было бы интересно с этим ознакомится.
Должен ли полиграфологи знать о первых двух способах сравнения выборок? Думаю, что и должны (кому, конечно, до этого есть интерес) знать их суть и "пощупать" их на практике. Тем более, что при определённых условиях их результаты могут быть использованы ровно как в случае с критерием знаков.
При множественных сравнениях возникает проблема увеличения групповой ошибки. Для её уменьшения используется коррекция уровня значимости Бонферрони и Данна - Шидака. Но эти коррекции приводят к уменьшению мощности тестов, вторая в меньшей степени. Процедура Холма в этом смысле более выгодно отличается от обеих.
Есть ли какой - практический смысл в знании полиграфологм всех подобных вещей я не знаю. Есть полиграфологи, которые не используют даже балльные оценки полиграмм. И при этом зарабатывают хорошие деньги. Если оценивать практический смысл в денежном эквиваленте, то, наверное, для практики полиграфолога вообще и статистика и даже арифметика не имеют практического значения. _________________ http://skl-ol.ru https://t.me/skl_ol
Последний раз редактировалось: York (Чт Мар 12, 2020 5:40 pm), всего редактировалось 1 раз
Добавлено: Чт Мар 12, 2020 5:30 pm Заголовок сообщения:
Хотелось бы сказать несколько слов про преобразовании наблюдаемых данных, так как это именно то, что делают полиграфологи при оценке полиграммы.
Преобразования наблюдаемых данных в статситике не редкость. Такие реобразования делают исходя из веских практических соображений. В рассмотрение вводят не сами наблюдаемые величины, а некоторую функцию от них - трансоформируют данные. Делают это, например, для приведения к нормальному виду остатков, устранения нелинейности шкал измерения для принятия гипотезы об аддитивности эффектов и т.д.
К таким преобразованиям относятся угловые трансформации, преобразования Фримана - Тьюки, Бокса - Кокса и другие.
В непараметрических ранговых, многомерных и перестановочных тестах переменные должны иметь симметричную функцию плотности распределения при нулевой гипотезе, поэтому наблюданные данные преобразуются в Соколе в ФОП - непрерыная функция аналог дискретных баллов, которая удовлетворяет этим требованиям в случае истинности нулевой гипотезц.. _________________ http://skl-ol.ru https://t.me/skl_ol
Прошу прощения у тех коллег, которым давал обещания, но не смог вовремя выполнить. Писал ВКР - получал новую специальность под пенсионный зад))) "Прикладная информатика". Специальность практическая и поэтому в рамках ВКР должен был спроектировать и закодировать информационную систему для организации, что отняло больше времени, чем рассчитывал. Но теперь оковы сброшены и постараюсь исправить ситуацию.
Выражаю признательность: А.Калафати, С.Поповичеву, А.Мошенскому, В.Рещикову, таинственному ВВ и другим коллегам, оказавшим интерес к моему начинанию и поддержавшим его.
Коллеги желающие получить программу могут писать мне на почту (получить - не купить).
Крайне положительно воспринимаются критика, замечания и пожелания. Принимаются идеи и предложения - те что возможно будет реализовать - будут реализованы.
предъявлений было четыре.... (просто в программе по умолчанию стоят все галочки)
пока что не стал выкладывать, т.к. это в рамках недавнего ПФИ
будет посвободней немного попробую что-то выложить из старого с полиграммами и обсчетом Сокола.
самому интересно
Владимир, в данном контексте вот вообще не интересно - давнее или не давнее... Нужны просто "голые" реакции... без описания фабулы... без вопросов... _________________ Мое почтение... $erP
................................... ЛЕГКО СОЛГАТЬ ТЯЖЕЛО
Юрий вот еще бы на примере этих 2-х обсчетов разжевать итоговые "цифиры", чтобы понимать картину в целом
Владимир (Питер)
Ради интереса вернул данные по дыханию и итоговые p-value улушчились
Главный полиграфный принцип гласит, что правдивый сильнее реагирует на контрольные (сравнения) вопросы, чем на проверочные. Лгущий - наооборот.
Этот принцип отражает не строгую,не функциональную, не детерменированную связь, а стохастическую, вероятностную. Т.е. эта связь не строгая и может нарушаться, иногда лгущий может отреагировать на контрольный сильнее по всем каналам (что редко случается), иногда по одному-двум каналам. Подобные нарушения принципа происходят и у правдивых. Как же установить, что опрашиваемый всё-таки реагирует сильнее на контрольные, если на полиграмме присутствуют реакции говорящие об обратном? Может так получилось, что это полиграмма обманщика, не смотря на то что преобладают "правдивые" реакции? Полиграфологи для этого складывают баллы. Но это чисто эмпирический метод, не имеющий достаточного теоретического обоснования. Даже если полиграфологу и понятно, что раз насчитано +20 баллов, то сильнее реакции на контрольные и можно сделать вывод о правдивости, то для действительно научного обоснования решения этого недостаточно. А вот если кроме этих баллов назвать: p-value < 0,1, то любой человек знакомый с методами матстата, и использующий их, поймёт без лишних слов о чём идёт речь и на чём основан вывод.
(В случае с баллами можно, конечно, и иначе обосновать принятие решения, например как С.В.Поповичев в своей статье, которая есть на этом форуме http://www.ld.eposgroup.ru/forum/viewtopic.php?t=13983 В ней хоть и не упоминается про априорную вероятность, но определение граничного балла вполне законно)
Это мат. статситика - база всей эксперементальной науки и не только. И в высокотехнологическом бизнесе, производстве, технике матстат активно используется. Полиграфология не может быть, и не должна быть исключением. Любые научные достижения основываются на достижениях сделанных ранее, и в других науках в том числе. В видео в теме о журнале об этом хорошо сказано. Это требование входит в принцип научности.
Опрашивая человека, мы должны подтвердить выполнение основного принципа с помощью матстата. Сначала выдвигается нулевая гипотеза - принцип не выполняется. То есть человек реагирует на оба типа вопроса в среднем одинаково. Иначе с вероятностью 0,5 он может отреагировать сильнее на контрольный, с вероятностью 0,5 сильнее на проверочный, не зависимо от того лжёт он или сообщает правду. Даже в этом случае полиграмма может получиться довольно разнообразной. Что такое нулевая, альтернативная гипотеза, как вычисляется и чем является p-value я кратко описал в статье в "Соколе" и в справке можно найти тоже самое.
П=С - это краткая запись нулевой гипотезы. П > C это краткая запись альтернативной ей гипотезы. С > П - это тоже альтернативная гипотеза. Они формулируются исходя из полученных данных, как это всегда делают полиграфологи. Но мало выдвинуть альтернативную гипотезу (+20 баллов это недостаточно), надо её ещё принять. Делается это на основе величины p-value. Если вычисленное значение p-value меньше заранее определённой величины, то альтекрнативная гипотеза принимается. Это означает, что выполнение основного полиграфного принципа подтверждается, и одновременно принимается решение о лживости или правдивости ответов. Если p-value больше заранее определённой величины, то результат "неопределённость"
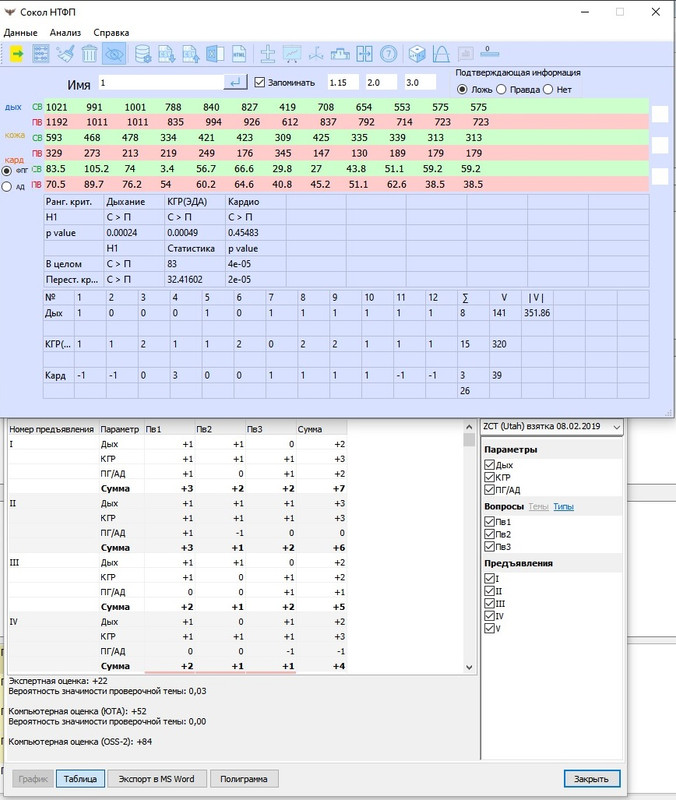
В программе альтернативные гипотезы вычисляются как отдельно по каналам так и в совокупности. Например, 0.15039 на картинке под "Дыхание" - это значение p-value (иначе называют достигаемый уровень значимости) для дыхания, 0.0048 - для КГР и т.д.
Вычисляется альтернативная гипотеза и p-value и в целом по совокупности каналов. Для вычисления всех этих значений используются непараметрические статистические тесты (использование параметрическиx - Стьюдента является необоснованным, короче - нельзя) Вилкосона и Перестановочный критерий. Последний более мощный, его использование возможно только с использованием компьютера. Если Вилкосона можно посчитатьь и вручную, то его нельзя вручную, в нём проделывается сотни тысяч вычислительных операций, поэтому он малоизвестен и мало ранее где использовался. Я нашёл в интернете статью об этом критерии, если надо дам ссылку, но сразу скажу, что там чистая матаматика-математика. В ней делается вывод, что мощность этого критерия сравнима с мощностью критерия Стъюдента. Как известно сильная сторона параметрических тестов - это их мощность.
В целом С > П 129 0.07472 - это Вилкоксон
Перест.кр.. С>П 10.26922 0.1261 - это Перестановочный критерий
Для проведения этих тестов все данные по каналам приводятся к "общему знаменателю" с помощью специальной функции ФОП (функция оценки полиграммы - моё название). С помщью ФОП данные по каналам приводятся к одному масштабу, как в случае с баллами. Аналог - нормировка или минимакс метод. ФОП обладает свойством симметричночти в случае справделивости нулевой гипотезы, что необходимо дря корректного проведения непараметрических статистических тестов. ФОП это аналог обычных, привычных баллов. Только баллы дискретные, а ФОП нерерывная функция. Она подобрана так, чтобы быть достаточно близкой к значению балла. Её значения суммируются по каналам и вопросам точно также как и баллы.
10.26922 - это значение ФОП для Вашей полиграммы. Она является наблюдаемой статистикой для Перестановочного критерия. Её нетрудно сосчитать в EXСEL.
Выделенное красным число совпадает с числом на скриншоте "Сокола"
Из формулы видно, что ФОП для каждого канала является безразмерной функцией с областью значений от -6 до +6. ФОП - это утроенное отношение разности реакций на сравниваемые вопросы к полусумме этих реакций (к среднему). Значения ФОП для одного вопроса и канала более 3 и менее -3 встречается достаточно редко.
Видно, что ФОП приводит информацию по каналам к одному масштабу. Баллы - это тоже приведение к одному масштабу.
Критическое значение p-value можно выбирать исходя из условий в которых проводится опрос. Например, если очень важно не обвинить невиновного, то критическое значение (или альфу - определённый уровень значимости) надо взять поменьше - 0.05, или уж в совсем важном случае 0.01 Если важно не пропустить виновного, то альфу можно взять побольше 0.1, а то и 0.2. Побольше альфу можно брать, когда полиграф не является окончательной инстанцией, а включён как звено в цепочку мероприятий. То есть используется для сужения круга и т.д. _________________ http://skl-ol.ru https://t.me/skl_ol
Вы не можете начинать темы Вы не можете отвечать на сообщения Вы не можете редактировать свои сообщения Вы не можете удалять свои сообщения Вы не можете голосовать в опросах You cannot attach files in this forum You cannot download files in this forum