 |
ПОЛИГРАФ - ФОРУМ
Для общения по теме " Детекция лжи "
|
| Предыдущая тема :: Следующая тема |
| Автор |
Сообщение |
$erP
Site Admin
Зарегистрирован: 29.06.2005
Сообщения: 7865
Откуда: Москва
|
 Добавлено: Сб Мар 11, 2023 1:56 pm Заголовок сообщения: Добавлено: Сб Мар 11, 2023 1:56 pm Заголовок сообщения: |
 |
|
| York писал(а): | | Но существует комбинаторная формула по которой можно расчитать такие таблицы для любого случая, для любогог количества повторов и количества стимулов. |
Почему именно комбинаторика, а не функция? Ведь основной изменяемый параметр - это средний ранг, а он не является дискретной величиной...
_________________
Мое почтение... $erP
................................... ЛЕГКО СОЛГАТЬ ТЯЖЕЛО |
|
| Вернуться к началу |
|
 |
York

Зарегистрирован: 29.09.2010
Сообщения: 2622
Откуда: Вологда
|
| Добавлено: Сб Мар 11, 2023 2:10 pm Заголовок сообщения: |
|
|
Почему и зачем использовался средний ранг мне не понятно. Этао таблица для частного случая с 10-ю повтрами. Повторов ровно 10. Поэтому средний ранг однозначно определяет суммарный. Например если средний 1,1 - умножаем на 10, и получаем суммарный ранг 11. Если средний 1,5 -умножаем на 10 и получаем 15. Таким образом заменяем средние ранги на дискретные значения.
Тот факт, что эта таблица для 10 повторов, факт того, что число 10 зафиксировано, ставит во взаимооднозначное соотвествие средний ранг дискретному суммарному рангу.
Поэтому зачем взят именно средний ранг не понятно. И этот средний ранг всё равно не распросранишь на другие количества повторов и количества стимулов, потому что там будут уже другие значения вероятностей.
Хотя...Может быть и планировалось распространить и на другие случаи, но потом Ликкен выяснил для себя, что делать так нельзя...и не сделал. Может быть поэтому он далее и не разрабатывал свою "неизвестную систему оценки". Но это уже мои домыслы. И эти домыслы в пользу того, что таблица была расчитана в лоб. И ни какой "утраченной формулы" не было. Ликкен не занимался коммерческой разработкой алгоритмов, не создавал программы для полигшрафологов, поэтому с чего бы ему скрывать эту формулу, а затем утратить её? Скорее наооборот, с целью лишний раз продемонсрировать научность своего подхода, он бы опубликовал её.
_________________
http://skl-ol.ru
Последний раз редактировалось: York (Сб Мар 11, 2023 2:25 pm), всего редактировалось 2 раз(а) |
|
| Вернуться к началу |
|
|
York
Зарегистрирован: 29.09.2010
Сообщения: 2622
Откуда: Вологда
|
| Добавлено: Сб Мар 11, 2023 2:19 pm Заголовок сообщения: |
|
|
Даже если Ликкен решил бы не публиковать формулу, то рассчитать таблицы для другого количества повторов стоило бы совсем ничего. Почему кроме этой для 10 повторов других не существует? Скорее потому, что в лоб расчитывать трудоёмкая задача. Хотя...Почему тогда для 10 случаев? Для 5-ти, или тем более для 2-3, было бы намного проще рассчитать в лоб.
_________________
http://skl-ol.ru |
|
| Вернуться к началу |
|
|
Александр Калафати
Зарегистрирован: 12.10.2011
Сообщения: 1852
Откуда: Москва
|
| Добавлено: Сб Мар 11, 2023 10:17 pm Заголовок сообщения: |
|
|
| York писал(а): | | Даже если Ликкен решил бы не публиковать формулу, то рассчитать таблицы для другого количества повторов стоило бы совсем ничего. Почему кроме этой для 10 повторов других не существует? Скорее потому, что в лоб расчитывать трудоёмкая задача. Хотя...Почему тогда для 10 случаев? Для 5-ти, или тем более для 2-3, было бы намного проще рассчитать в лоб. |
Причин может быть множество.
Как одна из:
Был математик, который посчитал для 10 повторов. Потом Ликкен с ним поругался, таблицу показал, ссылок на математика не привел. Больше в этой области не работал/ нашел другого человека.
Сергей Владимирович, спасибо большое! Очень интересно. Готовая статья для ДЛ)
_________________
Быть, а не казаться.
http://polygraph-triumph.ru/ |
|
| Вернуться к началу |
|
|
York
Зарегистрирован: 29.09.2010
Сообщения: 2622
Откуда: Вологда
|
| Добавлено: Вс Мар 12, 2023 12:08 pm Заголовок сообщения: |
|
|
| Александр Калафати писал(а): |
Сергей Владимирович, спасибо большое! Очень интересно. Готовая статья для ДЛ) |
Плюсуюсь, ставлю лайки и огни, короче полностью согласен )
_________________
http://skl-ol.ru |
|
| Вернуться к началу |
|
|
Александр Калафати
Зарегистрирован: 12.10.2011
Сообщения: 1852
Откуда: Москва
|
| Добавлено: Вс Мар 12, 2023 12:27 pm Заголовок сообщения: |
|
|
Юрий, а от Вас комментарии , как от математика) это добавит нюансов и глубины. вот и совместный труд
_________________
Быть, а не казаться.
http://polygraph-triumph.ru/ |
|
| Вернуться к началу |
|
|
$erP
Site Admin
Зарегистрирован: 29.06.2005
Сообщения: 7865
Откуда: Москва
|
| Добавлено: Вс Мар 12, 2023 12:36 pm Заголовок сообщения: |
|
|
Коллеги, спасибо вам большое за лайки и оценку...
Но пока ещё тема не закрыта... есть ещё что сказать... и самые сложности, реально, еще впереди...
P.S.
| Александр Калафати писал(а): | | Готовая статья для ДЛ) |
Ну... в свете последних событий это теперь большой вопрос...
_________________
Мое почтение... $erP
................................... ЛЕГКО СОЛГАТЬ ТЯЖЕЛО |
|
| Вернуться к началу |
|
|
York
Зарегистрирован: 29.09.2010
Сообщения: 2622
Откуда: Вологда
|
| Добавлено: Вс Мар 12, 2023 1:00 pm Заголовок сообщения: |
|
|
| $erP писал(а): |
P.S.
| Александр Калафати писал(а): | | Готовая статья для ДЛ) |
Ну... в свете последних событий это теперь большой вопрос... |
Если не секрет, то что за события? Они имеют отношение к журналу?
_________________
http://skl-ol.ru |
|
| Вернуться к началу |
|
|
$erP
Site Admin
Зарегистрирован: 29.06.2005
Сообщения: 7865
Откуда: Москва
|
| Добавлено: Вс Мар 12, 2023 7:18 pm Заголовок сообщения: |
|
|
| York писал(а): | | Подобный расчёт это комбинаторная задача. |
У меня есть некоторые сомнения на этот счёт.
Перед последним... финишным рывком по теме "неизвестный способ оценки" GKT... позволю себе высказать сомнения в отношении комбинаторного характера "формулы Ликкена"... той "формулы Ликкена", которую использовал сам Ликкен, а не той "формулы Ликкена", которую имеют в виду авторы 4х томника…
У меня по этому поводу есть несколько аргументов.
1. Если полагать, что для оценки вероятностей Ликкен таки использовал "комбинаторный подход", а в расчётную формулу входили параметры R (суммарный ранг), N (количество проверяемых признаков) и M (количество ранжируемых вопросов в тесте), то вообще кажется нелогичным то, как он потом представлял результаты своих вычислений.
Если итоговая вероятность определяется, прежде суммарным рангом R, то зачем Ликкену давать таблицу, в которой представлена зависимость вероятности от среднего ранга R/N? Что за блажь такая?
Если вероятность определяется R, то составлять таблицу зависимости вероятности от R/N – только путаницу наводить… И заставлять пользователей проделывать такой расчёт только ради того, чтобы посмотреть в таблицу – лишний шаг… с риском чего-то напутать... И это при том, что мы пока имеем в виду представленную для наглядности таблицу Ликкена применительно к 10ти признакам, когда разделить суммарный ранг 12 или 19 или 27 на 10 не представляется сложным. А если бы количество признаков было не 10, а 7? или 11? или, не дай Бог, 13? Ради чего устраивать людям этот геморой?
Хочу наглядно проиллюстрировать свою мысль тем, как авторы 4х-томника запутались сами и запутали других окончательно в попытке скрестить "ежа и ужа" – то есть свой суммарный ранг и Ликкеновский средний ранг.
Посмотрим на следующие две детали.
Первая деталь. Можно посмотреть здесь. Таблица вероятностей от Ликкена имеет оригинальное название: "Probabilities of Various Mean-Rank Scores for Innocent Subject on a Ten-Item GKT" – "Таблица зависимости вероятности от среднего ранга в тесте с 10ю признаками для Невиновного Субъекта". Термин "средний ранг" прописан Ликкеным четко, без двусмысленностей. Авторы 4х томника же написали название таблицы на свой лад: "Таблица оценки вероятности получения конкретного суммарного ранга неосведомленным тестируем по результатам ТФО с использованием 10-ти проверочных признаков (Из книги Д. Ликкена «Дрожь в крови», 1981 г.)".
Вторая деталь. В названии таблицы 10 [5, стр. 83], сравнивающей данные Ликкена со данными, полученными в результате расчётов по "комбинаторной формуле", авторы пишут: "Вероятность случайного получения суммарного ранга проверочных признаков…". Но в самой таблице данных суммарного ранга как таковых и нет; название первого столбца таблицы – "Средний ранг, полученный для десяти проверочных признаков", и содержит он действительно данные средних рангов, а не суммарных рангов.
В общем, считать-пересчитывать из суммарного ранга средний ранг – это тот еще гемор. Для того, чтобы делать такой пересчёт, нужны весомые основания. И единственным весомым основанием для такого пересчета является необходимость "вставлять" данные среднего ранга в какую-то расчетную формулу. Только тогда вычисление среднего ранга – важный шаг, потому что этот параметр учитывается в формуле вычисления вероятности.
И… да… риторический вопрос… А почему у Ликкена нигде нет намёка на то, что в вычисляемой им вероятности получить невиновным проверяемым некоторый средний ранг или меньше должен участвовать такой параметр, как N - количество вопросов в тесте? В "комбинаторной формуле" он есть... А у Ликкена куда пропал? А, может, его у Ликкена и нет вовсе?
2. На то, что сам Ликкен вряд ли использовал "комбинаторный подход", указывают используемые им обозначения в своей таблице.
Правый столбец таблицы обозначен как "кумулятивная вероятность". И в примечании к таблице Ликкен дает соответствующие комментарии: "Для примера, есть примерно 16 шансов из 1000, что субъект без виновных знаний даст реакции на релевантные вопросы, которые получат средний ранг 2 или меньше".
То есть очевидно, что Ликкен в этом моменте разбирается... и говорит он не просто о вероятности, а о значениях p-value, что указывает на использование Ликкеным в своих расчётах какой-то функции распределения вероятности, а не комбинаторики.
Опять же, на контрасте для показательности… Авторы 4х томника, пользуясь комбинаторной формулой, видимо, имеют искаженное представление о "физическом смысле" p-value. В той же таблице 10 [5, стр. 83] они достаточно свободно переименовали "кумулятивную вероятность" Ликкена в "Вероятность случайности получения ранга", а "Вероятность случайности получения ранга" через вычитание из единицы и преобразование в проценты превратили в "Достоверность осведомлённости". В их представлении это, видимо, примерно одно и тоже… В качестве объяснения напрашивается, что авторы 4х томника со своим "комбинаторным подходом" таки не до конца поняли математику Ликкена.
В конце концов, разработчики PolySrore'a для вычисления вероятностей пользуются "не комбинаторной" формулой... см.
Dale E. Olsen and all "Computerized Polygraph Scoring System"
Кирчер с Раскиным в своих работах для вычисления вероятностей тоже решают не комбинаторную задачу, а пользуются обычной формулой нормального распределения вероятностей... см. John C. Kircher and David C. Raskin, "Human Versus Computerized Evaluations of Polygraph Data in a Laboratory Setting".
3. Александр Борисович Пеленицын разработал свою систему оценки реакций, которая легла в основу ChanceCalc, очень давно (сужу не только по его высказываниям в 4х томнике, но и по тому, что у меня есть презентация по СС, создание файла датируется 1997 годом, последние изменения вносились в 2007 году). Система оценки разработана как ответ на следующие вопросы:
Ставим вопросы:
* Какова вероятность того, что при данном значении суммарного ранга r реакции на стимул были случайными?
* Какова вероятность неслучайности появления реакции на стимул, получивший суммарный ранг r, при данных m и n ?
* Ответ получаем с помощью распределения вероятности неслучайности реакций:
P(r) = f (m, n, r)
Появившаяся в результате этой действительно сложной исследовательской работы формула вычисления вероятности неслучайности реакции (я позволю себе использовать авторские термины) относится к комбинаторике. Её особенностью является универсальность, то есть предназначенность не только для оценки теста строго определённого формата - например, ТФО – а применимость ко всем тестовым форматам.
Я хочу этими объяснениями аргументировать ту свою мысль, что у Александра Борисовича, похоже, не было никакой целенаправленно специальной работы по расшифровке именно "формулы Ликкена", которую тот применял в качестве метода оценки среднего ранга. В принципе, в 4х томнике авторы и не говорят, что они вычислили "формулу Ликкена". Они говорят, что в своих вычислениях приблизились к значениям, полученным Ликкеном. Но они и не скрывают наличие расхождений в данных, получаемых по своей формуле, с данными оригинальной таблицы Ликкена. И объясняют эти расхождения разными математическими подходами, положенными в основу Ликкеным и в СС [5, стр. 85]: Из таблицы следует, что значения вероятностей, вычисленных с помощью «неизвестной» системы Д. Ликкена и системы СС незначительно, но все же в отдельных случаях различаются на уровне второго знака после запятой. Это вполне естественно, так как обе системы оценки построены на основе разных математических моделей, описывающих процесс проведения ТФО.
**************************
Данным пассажем я ни в коем случае не хочу сказать, что СС применительно к тестам ТФО считает плохо… нет... ни в коем случае...
С моей точки зрения всё это означает, подходы, используемые Ликкеным и СС для вычисления вероятностей, действительно принципиально разные...
И что быть уверенным в том, что значения, получаемые с помощью СС, совпадают со значениями, вычисленными по "формуле Ликкена", можно только в пределах известных для проверки параметров: количество признаков 10, количество вопросов в тесте вместе с релевантным 5, средний ранг на релевантный вопрос не превышает 3.
Наличие даже небольших расхождений в данных при известных параметрах даёт основание для предположения, что изменение любого из этих параметров приведёт к получению ещё больших расхождений в данных, вычисленных по СС и по "формуле Ликкена"... если бы таковую удалось бы получить...
_________________
Мое почтение... $erP
................................... ЛЕГКО СОЛГАТЬ ТЯЖЕЛО |
|
| Вернуться к началу |
|
|
York
Зарегистрирован: 29.09.2010
Сообщения: 2622
Откуда: Вологда
|
| Добавлено: Пн Мар 13, 2023 12:29 am Заголовок сообщения: |
|
|
| Цитата: |
1. Если полагать, что для оценки вероятностей Ликкен таки использовал "комбинаторный подход", а в расчётную формулу входили параметры R (суммарный ранг), N (количество проверяемых признаков) и M (количество ранжируемых вопросов в тесте), то вообще кажется нелогичным то, как он потом представлял результаты своих вычислений.
Если итоговая вероятность определяется, прежде суммарным рангом R, то зачем Ликкену давать таблицу, в которой представлена зависимость вероятности от среднего ранга R/N? Что за блажь такая?
|
Ликкен на математик. Все американские полигарфологи не математики. У них есть математической блажи в статьях в товарных количествах.
| Цитата: | | В общем, считать-пересчитывать из суммарного ранга средний ранг – это тот еще гемор. Для того, чтобы делать такой пересчёт, нужны весомые основания. И единственным весомым основанием для такого пересчета является необходимость "вставлять" данные среднего ранга в какую-то расчетную формулу. Только тогда вычисление среднего ранга – важный шаг, потому что этот параметр учитывается в формуле вычисления вероятности. |
Таблица имеется только одна. Для десяти случаев. Умножить на десять, поделить на десять - тут точно есть какой-то гемор? Вроде бы нет никакого гемора. И почему надо говорить о необходимости вставить средний ранг в какую-то неведомую формулу, приводя основанием какой то неоднозначный гемор?
| Цитата: | | И… да… риторический вопрос… А почему у Ликкена нигде нет намёка на то, что в вычисляемой им вероятности получить невиновным проверяемым некоторый средний ранг или меньше должен участвовать такой параметр, как N - количество вопросов в тесте? В "комбинаторной формуле" он есть... А у Ликкена куда пропал? А, может, его у Ликкена и нет вовсе? |
Это можно было бы спросить у Ликкена- почему он не упоминает о количестве вопросов в тесте. Но на соновании того, что Ликкен не упомянул о количестве вопросов в тесте никаких выводов делать нельзя. Мало ли почему он не упомянул? Может быть считал, что и так всё понятно о каком количестве речь идёт. Вот математик бы обязательно написал бы, что эта таблица для N вопросв. Или, если на то пошло, то обязательно бы написал, что эта таблица для любого количества вопросв. Но Ликкен не математик, как и другие американские полиграфологи. Не математики часто считают, что подобной фигне не зачем уделять внимание. Этим они отличаются от математиков.
| Цитата: |
2. На то, что сам Ликкен вряд ли использовал "комбинаторный подход", указывают используемые им обозначения в своей таблице.
Правый столбец таблицы обозначен как "кумулятивная вероятность". И в примечании к таблице Ликкен дает соответствующие комментарии: "Для примера, есть примерно 16 шансов из 1000, что субъект без виновных знаний даст реакции на релевантные вопросы, которые получат средний ранг 2 или меньше".
То есть очевидно, что Ликкен в этом моменте разбирается... и говорит он не просто о вероятности, а о значениях p-value, что указывает на использование Ликкеным в своих расчётах какой-то функции распределения вероятности, а не комбинаторики.
|
Вот совсем, от слова вообще, это не указывает на то, что Ликкен в "своих" (в скобках это потому, что я на 100% уверен, что основное не он считал) расчётах использовал кукую-то функцию распределения вероятнотей, и не использовал комбинаторику?
Хотя тут надо уточнить. А почему противоставляется "функция распределения вероятностей" и комбинаторика, как нечто несовместимое? На чём основано это противопоставление?
Из чего следует, что то, что можно назвать "функцией распределения вероятностей" не расчитывается комбинаторным способом? "Известная" все ученикам НШДЛ формула Бозе-Эйнштейна - это вполне себе комбинаторная формула, которая задаёт распределение Бозе-Эёнштейна. Прошу не путать с Бозе-Эйнштейна из статистичесой физики - это другое).
$erP вот Вы писали
| Цитата: |
Почему именно комбинаторика, а не функция? Ведь основной изменяемый параметр - это средний ранг, а он не является дискретной величиной...
|
И видимо это послужило отправной точкой...
А почему Вы решили, что средний ранг это не дискретная случайная величина? Предположу, что на основании того, что средний ранг это не целое число, а рациональное, дробное число. Так ведь принадлежность к определённому множеству чисел не является определяющим признаком дискретной случайной величины.
Можно посмотреть курс "Математика для полиграфологов". Там есть определение дискретной случайной величины:
Случайную величину ξ называют дискретной, если она принимает конечное или счётное число значений.
Для десяти повторов (и любого другого количества повторов) и суммарный ранг, и средний ранг (между ними есть взаимооднозначное соответсвие) принимают конечное число значений. Иначе -суммарный ранг и средний ранг- это дискретные случайные величины.
Минимальный суммарный ранг равен 10, что соотвествует среднему рангу 1. Максимальный суммарный ранг 50, что соотвествует среднему рангу 5. Вот почему Ликкен остановился в своей таблице на среднем ранге 3, а не довёл её до конца? Это знает только сам Ликкен. И нельзя на этом факте строит какие то предположения.
Я понимаю, что для Вас я ноль без палочки...Но определение это взято из учебника Печёкина "Теория вероятностей и математическая статистика" МГТУ имени Баумана. Хотя могу и ошибаться, так как я использовал несколько учебников, но этот был основным.
Можно взять любой другой учебник. Но только для математиков, на крайний случай для технических вузов. Что могут написать в учебнике по математике для психологов я не знаю. Я бы сам не стал опираться на учебник по психологии, написанный математиком для студентов математиков.
В итоге имеем, что и суммарный ранг и средний ранг это дискретные случайные величины. Было бы удивительно, если бы было иначе, учитывая их взаимооднозначное соответсввие.
Для дискретной случайной величины вполне себе можно расчитать комбинаторным способом то, что можно называется функцией распределения вероятностей. Если говрить о таблице Ликкена, то первые два столбца этой таблицы ("Средний ранг" и "Вероятность") представляют собой, что называется в математике, ряд распределения дискретной случайной величины (иногда называют закон распределения дискретной случайной величины, но закон распределения это более широкее понятие). А вот третий столбец - это и есть функция распределения вероятностей дискретной случайной величины, что прямо следует из определения (можно посмотреть в курсе "Математика для полиграфологов" или учебнике).
Ну не математик Ликкен, поэтому он озаглавил третий столбец "Куммулятивная вероятность" (а не ФРВ), что в данном случае и является функцией распределения вероятностей (а может англосаксы не делают разницы), которая вычисляется суммированием вероятностей во втором столбце. то что написано в сноске у Ликкена полностью соотвествует определению функции распределения вероятностей. Вы говорите о третьем столбце как о p-value...P-значение имеет связь с функцией распределения вероятностей. но это не одно и то же. При некоторых ограничениях можно говрить о конкретном значении функции распределения вероятностей как о значении p-value (стоит учитывать, что по отношению к дискретным величинам понятие p-value используют только полиграфологи, сначала американские, а вслед за ними и российские). Поэтому нет никакого основания говорить о не комбинаторном происхождении таблицы Ликкена.
Можно ещё написать почему её происхождение комбинаторное, но тут я точно понят не буду, поэтому мало смысла писать. Хотя...задача эта - в чистом виде комбинаторная задача...комбинаторней просто некуда...
| Цитата: |
Опять же, на контрасте для показательности… Авторы 4х томника, пользуясь комбинаторной формулой, видимо, имеют искаженное представление о "физическом смысле" p-value. В той же таблице 10 [5, стр. 83] они достаточно свободно переименовали "кумулятивную вероятность" Ликкена в "Вероятность случайности получения ранга", а "Вероятность случайности получения ранга" через вычитание из единицы и преобразование в проценты превратили в "Достоверность осведомлённости". В их представлении это, видимо, примерно одно и тоже… В качестве объяснения напрашивается, что авторы 4х томника со своим "комбинаторным подходом" таки не до конца поняли математику Ликкена.
|
Ну имеют искажённое представление о p-value...Переименовывают в фирменные "вероятности неслучайности" и "вероятности случайности" и "достоверности"...и не поняли математику Ликкена...Так как сами написали в 4-х томнике "...это естественно, так как обе системы оценки построены на основании разных математических моделеей..." Это они написали на основании расхождения табичных данных с данными вычисленными с помощью ChanceCalc во втором знаке.
Но дело в том, что в таблице у Ликкена начиная со среднего ранга 2.3 присутсвует ошибка в третьем столбце,которая наверняка возникла из-за ошибки округления. А у авторов 4-х четырёхтомника округления все сделаны правильно (таблица 10, страница 83) и отсюда возникло некоторое расхождение с табличными данными Ликкена.
Математик первым делом начнёт искать возможные ошибки в данных, проверять не возникли ли они из-за элеметнтарных арифметических действий и округлений. И уж ни как не будет делать глобальных выводов, если на лицо ошибки округлений.
| Цитата: |
В конце концов, разработчики PolySrore'a для вычисления вероятностей пользуются "не комбинаторной" формулой... см.
Dale E. Olsen and all "Computerized Polygraph Scoring System"
Кирчер с Раскиным в своих работах для вычисления вероятностей тоже решают не комбинаторную задачу, а пользуются обычной формулой нормального распределения вероятностей... см. John C. Kircher and David C. Raskin, "Human Versus Computerized Evaluations of Polygraph Data in a Laboratory Setting".
|
Можно использовать самые разные вещи в задаче классификации: и логистическую регресию и нормальное распределение, включая многомерное нормальное, и ещё множестов вещей использовать. Но задача подсчёта комбинаций рангов - это комбинаторная задача. Подсчёт комбинаций рангов равносилен вычислению вероятностей в таблице ЛИккена.
| Цитата: |
Ставим вопросы:
* Какова вероятность того, что при данном значении суммарного ранга r реакции на стимул были случайными?
* Какова вероятность неслучайности появления реакции на стимул, получивший суммарный ранг r, при данных m и n ?
* Ответ получаем с помощью распределения вероятности неслучайности реакций:
P(r) = f (m, n, r)
Появившаяся в результате этой действительно сложной исследовательской работы формула вычисления вероятности неслучайности реакции (я позволю себе использовать авторские термины) относится к комбинаторике. Её особенностью является универсальность, то есть предназначенность не только для оценки теста строго определённого формата - например, ТФО – а применимость ко всем тестовым форматам.
|
Вопросы эти не математические. Точнее на языке математики они так не формулируются. Может быть они психологические, психофизиологические, полиграфические...Но не математические. А поэтому должны рещаться психологическими, психофизиологическими, полиграфическими методами, но не математическими. Математика тут бессильна.
И кстати, ни о какой универсальности речи нет. Только ТФО с одним Пв. Для ТВС можно лишь гистограмму построить.
| Цитата: |
Я хочу этими объяснениями аргументировать ту свою мысль, что у Александра Борисовича, похоже, не было никакой целенаправленно специальной работы по расшифровке именно "формулы Ликкена", которую тот применял в качестве метода оценки среднего ранга. В принципе, в 4х томнике авторы и не говорят, что они вычислили "формулу Ликкена". Они говорят, что в своих вычислениях приблизились к значениям, полученным Ликкеном. Но они и не скрывают наличие расхождений в данных, получаемых по своей формуле, с данными оригинальной таблицы Ликкена. И объясняют эти расхождения разными математическими подходами, положенными в основу Ликкеным и в СС [5, стр. 85]: Из таблицы следует, что значения вероятностей, вычисленных с помощью «неизвестной» системы Д. Ликкена и системы СС незначительно, но все же в отдельных случаях различаются на уровне второго знака после запятой. Это вполне естественно, так как обе системы оценки построены на основе разных математических моделей, описывающих процесс проведения ТФО.
|
Причина незначительного рассхождения это ошибка в таблице Ликкена. Маленькая, очень человечная ошибка в округлении. На её основе воздвигаются теории.
| Цитата: |
Наличие даже небольших расхождений в данных при известных параметрах даёт основание для предположения, что изменение любого из этих параметров приведёт к получению ещё больших расхождений в данных, вычисленных по СС и по "формуле Ликкена"... если бы таковую удалось бы получить...
|
Ошибка в округлении числа даёт основание сделать вывод, что будут ещё большие расхождения. Ну так то да ...если ещё наломать с округлениями, то ошибка накопится и расхождения увеличатся.
_________________
http://skl-ol.ru
Последний раз редактировалось: York (Пн Мар 13, 2023 11:10 am), всего редактировалось 2 раз(а) |
|
| Вернуться к началу |
|
|
Александр Калафати
Зарегистрирован: 12.10.2011
Сообщения: 1852
Откуда: Москва
|
| Добавлено: Пн Мар 13, 2023 8:44 am Заголовок сообщения: |
|
|
| $erP писал(а): |
Я хочу этими объяснениями аргументировать ту свою мысль, что у Александра Борисовича, похоже, не было никакой целенаправленно специальной работы по расшифровке именно "формулы Ликкена", которую тот применял в качестве метода оценки среднего ранга. ... |
Есть вебинар Пеленицына, где он в течение 4х часов рассказывает как он целенаправленно пытался расшифровать "формулу Ликкена". Подрядил для этого своего брата и кафедру МГУ. И работали те аж годами.
Или Вы хотите сказать, что Пеленицын говорит вещи несовместимые с этикой полиграфолога?
_________________
Быть, а не казаться.
http://polygraph-triumph.ru/ |
|
| Вернуться к началу |
|
|
ЮРЬЕВ

Зарегистрирован: 18.04.2006
Сообщения: 3434
Откуда: Краснодар
|
| Добавлено: Пн Мар 13, 2023 10:39 am Заголовок сообщения: |
|
|
"Если звезды зажигаются, значит, это кому-то нужно..."
Я одного не пойму, то, что в таблице Ликкена две цифры не правильно округлены...от того, что Пеленицын расшифровал или не расшифровал формулу Ликкена...что-то меняется принципиально?
Это значит, что GKT, ТФО или POT не работали и то, что они работают, только кажется?
Или...что?
Последний раз редактировалось: ЮРЬЕВ (Пн Мар 13, 2023 10:42 am), всего редактировалось 1 раз |
|
| Вернуться к началу |
|
|
York
Зарегистрирован: 29.09.2010
Сообщения: 2622
Откуда: Вологда
|
| Добавлено: Пн Мар 13, 2023 10:40 am Заголовок сообщения: |
|
|
Предлагаю посмотреть на таблицу Ликкена внимательно и увидеть ошибки округления.
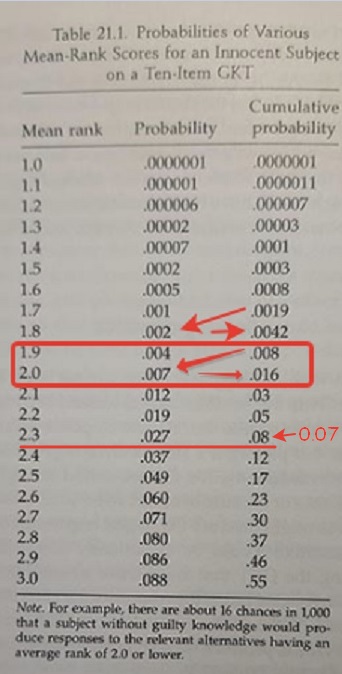
Главный столбец значения которого расчитываются это "Вероятность". Столбец "Кумулятивная вероятность" получается из значений столбца "Вероятность" простым суммированием его значений.
Надо сразу сказать, что в одной аблице округлять числа до разных разрядов, а потом их суммировать - это неправильно. Это неизбежно приведёт к накоплению ошибок. И это накопление можно увидеть своими глазами. До ранга 1.7 всё вроде бы нормально, но в 1.7 ошибки округления дают себя знать. Для 1.7 в третем столбце имеем 0.0019, которое должно быть равно 0.0008 + 0.001 = 0.0018. Но эти числа не равны. Никакими округлениями 0.0018 не округлишь до 0.0019. И дальше та же история 0.0019 + 0.002 = 0.0039. А в таблице в тертьем столюце для 1.8 стоит 0.0042. 0.0039 никак не округлишь до 0.0042. На самом деле 0.0019 и 0.0042 это правильные значения, и они "натянуты" в таблице, для того, что бы ошибки в округлениях не начали бы давать очень сильные расхождения с правильными значениями.
А вот в 2.3 правильное значение 0.0737 и если округлять до сотых, то должно в таблице стоять 0.07. Но по какой-то причине забыли произвести "натягивание" правильного значения как для рангов 1.7, 1.8, 1.9. А сложили 0.05 + 0.027 = 0.077 и округлили его до 0.08. Вот тут то и пошли расхождения таблицы Ликкена и таблицы Пелиницина, потому что ошибка в одну сотую стала передаваться дальше. И это расхождение явилось основание для утверждения о разных математических моделях. А на самом деле речь идёт об ошибках округления чисел.
А для ранга 2.8 снова произведено "натягивание" правильного округлённого значения "Кумулятивной вероятности" и ошибку в одну сотую убрали.
_________________
http://skl-ol.ru |
|
| Вернуться к началу |
|
|
York
Зарегистрирован: 29.09.2010
Сообщения: 2622
Откуда: Вологда
|
| Добавлено: Пн Мар 13, 2023 10:55 am Заголовок сообщения: |
|
|
| ЮРЬЕВ писал(а): | "Если звезды зажигаются, значит, это кому-то нужно..."
Я одного не пойму, то, что в таблице Ликкена две цифры не правильно округлены...от того, что Пеленицын расшифровал или не расшифровал формулу Ликкена...что-то меняется принципиально?
Это значит, что GKT, ТФО или POT не работали и то, что они работают, только кажется?
Или...что? |
Никакой угроза для рядов нет ) Просто имеются теории, что у Ликкена было своя ликкеновская формула. Главный довод - это расхождения в табличных данных.
_________________
http://skl-ol.ru |
|
| Вернуться к началу |
|
|
ЮРЬЕВ
Зарегистрирован: 18.04.2006
Сообщения: 3434
Откуда: Краснодар
|
| Добавлено: Пн Мар 13, 2023 11:49 am Заголовок сообщения: |
|
|
Понятно, спасибо.
В свое время, чтобы использовать ряды, оказалось достаточно абзаца из Варламовской книги:
"Элементарные расчеты показывают, что если будут проведены только два теста по пять вопросов, вероятность случайной реакции на значимый вопрос будет составлять 4%, а при десяти тестах - одну десятимиллионную".
Возможно, Варламов имел в виду именно эту Ликкеновскую таблицу.
А зачем нужна Ликкеновская формула? |
|
| Вернуться к началу |
|
|
|
|
Вы не можете начинать темы
Вы не можете отвечать на сообщения
Вы не можете редактировать свои сообщения
Вы не можете удалять свои сообщения
Вы не можете голосовать в опросах
You cannot attach files in this forum
You cannot download files in this forum
|
Powered by phpBB © 2001, 2005 phpBB Group



|

