Добавлено: Пт Сен 30, 2022 2:37 pm Заголовок сообщения:
Да сейчас эта ошибка исправлена. Версия выложена исправленая. Хотя возникла некотороя проблема. Из-за особенностей сборки последней версий посыпались ошибки. Сейчас перепроверяю выложенные для скачивания программы уже в который раз. Перепроверяю и новых не вижу. Так что если скачаете и вдруг встретятся ошибки сообщаате мне. _________________ http://skl-ol.ru
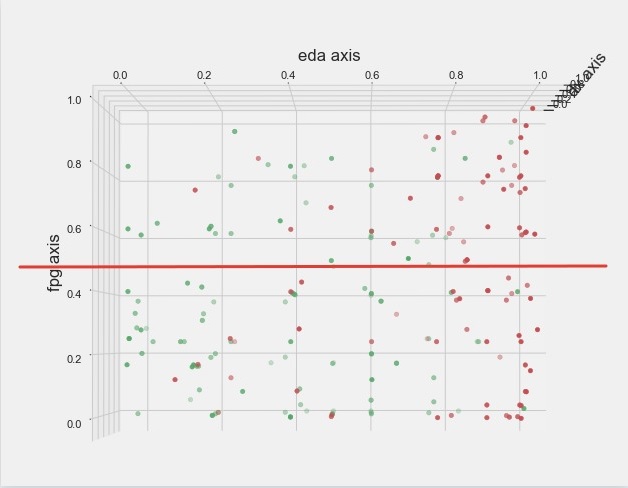
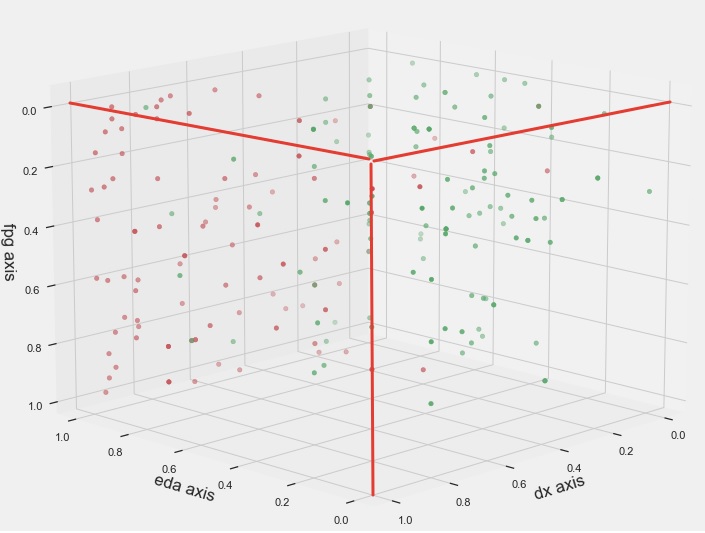
Изучаю данные Комбикалка полученные на ТЗВ по раскрытым уголовным делам. Имеется 120 ТЗВ с правдой и 91 ТЗВ с ложью. Полиграммы записаны на Диане, каналы: Дыхание (dx), КГР (eda), ФПГ (fpg). Самый простой и наглядно-доходчивый анализ это визуальный. Построил трёхмерную диаграмму рассеяния. Красные точки - реакции на ПВ лгущих лиц. Зелёные - правдивых.
Посмотрим как разделяет лгущих ФПГ. Видно что относительно красной линии красные и зелённые точки распределены примерно равномерно, примерно одинаковое число точек ниже и выше линии.
Вывод спазм ФПГ мало полезен для дискриминации опрашиваемых, а может быть и вреден так как фактически дает шум.
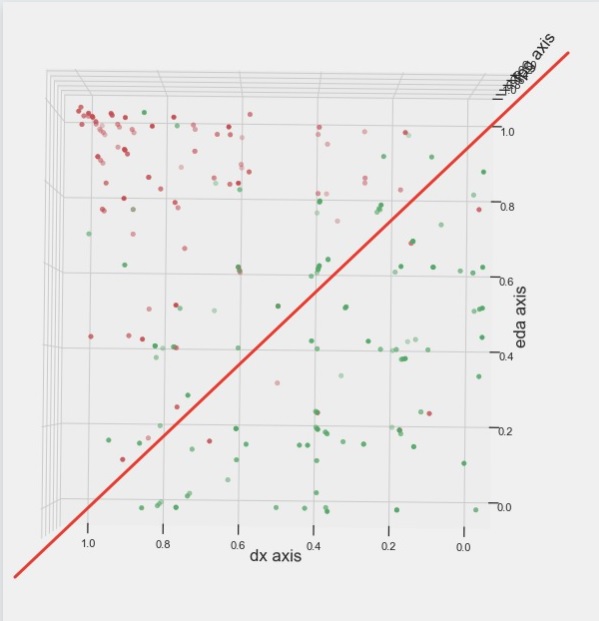
Другая картина в случае Дыхания и КГР
Почти все красные точки (реакции лживых) выше красной линии. А примерно две третьих зелёных точек (реакции правдивых) ниже красной линии.
Из этого визульного анализа следует оптимальный способ разделения полиграмм ТЗВ для комбикалка при отсутсвии Манжеты _________________ http://skl-ol.ru
ФПГ - "спазм" действительно странный параметр. Валидный параметр это сила спазма. Т.е. соотношение начальных условий к минимальному значению на участке анализа. А брать только минимальное значение на участке это афизиологично. _________________ Быть, а не казаться.
http://polygraph-triumph.ru/
Добавлено: Чт Окт 06, 2022 12:32 am Заголовок сообщения:
У многих пользователей возникают проблемы с активацией программы. Выкладываю видео в котором показано как провести активацию. Разобраны ситуации и причины когда не удается активировать программу
Зашла тут речь о том, что иногда алгоритмы могут вести себя необычно, непонятно. Порой живой ум энергичного полиграфолога может на одном единственном примере сделать глобальный вывод о том, что алгоритмы ерунда, вот мол пример и я крайне разочарован. Интересно, что относительно своих собственных суждений такие скоропалительные выводы никогда не делаются. Но последнее замечание касается психологии полиграфологов, как правило принимающие решение в состоянии существенной неопределенности.
Но прежде чем делать скоропалительные выводы (относительно любого явления) предлагаю посмотреть на полиграфные тесты с точки зрения статистики. А с точки зрения статистики слабость полиграфных тестов заключается в том, что тесты дают маленькие выборки данных.
В чем же тут загвоздка? А дело в том, что чем больше выборка тем лучше она представляет свойства генеральной совокупности. Чем больше выборка тем устойчивей, даваемая ей картина, по отношению к каким-то случайным отклонениям.
Чем меньше выборка, то как правило она хуже отражает свойства ген.совокупности, а получаемый на её основе результат меенее устойчив к случайным отклонениям от среднего, То есть существенное отклонение в одном каком-то предъявлении стимула, или тем более не одном, может сильно повлиять на результат любого алгоритма.
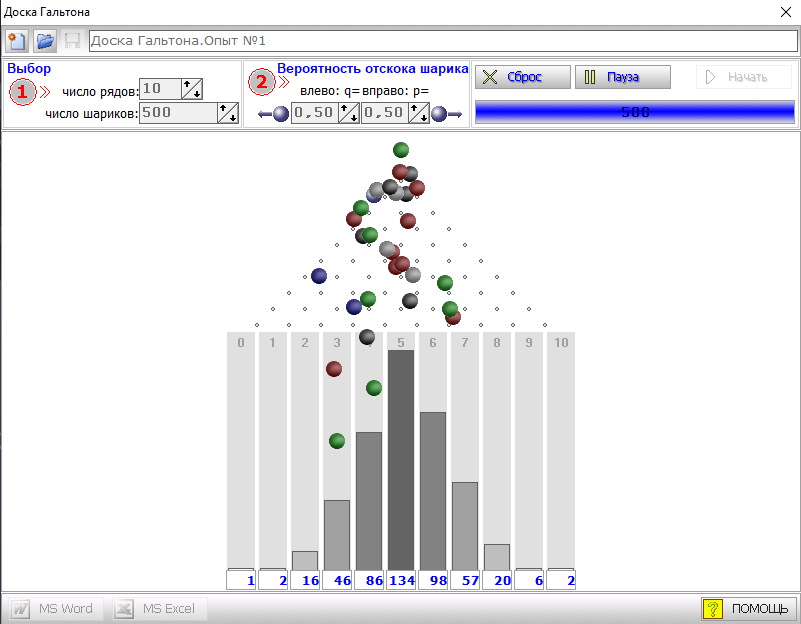
В принципе, такие вещи можно не объяснять, а продемонстрировать визуально. Порою визуально можно понять быстрее и легче, нежели доходить до этого логическим путем. Но даже для визуального восприятия надо знать немножко теории, а именно познакомиться с доской Гальтона
Можно посмотреть видео
В видео очень большое количество шариков - огромная выборка. И поэтому она очень хорошо отражает свойства ген совокупности - нормального распределения.
А что получиться, если выборка будет небольшой? Давайте посмотрим с помощью компьютерной модели доски Гальтона. Пусть сначала будет большая выборка - 500 шариков. Имеем следующую картину.
Видно, что большая выборка хорощо отражает свойства ген.совокупности. Количество шаров упавшее в ячейки мало отличается от того, что ожидалось исходя из свойств нормального распределения. Поэтому имеем хороший колокол нормального распределения.
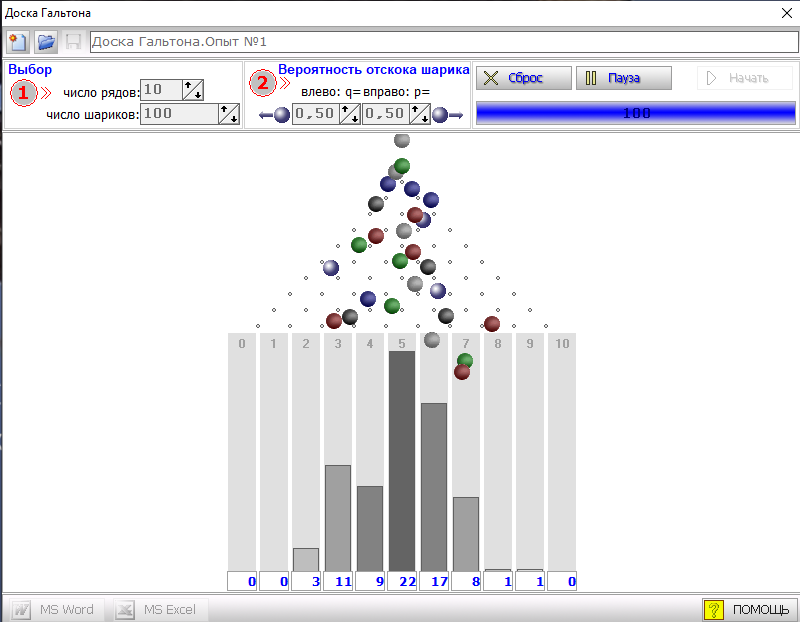
Возьмем сто шариков.
Картинка еще достаточно хорошо схожа с колоколом нормального распределения, но отклонения количества шаров в ячейках уже сильнее отличается от ожидаемого.
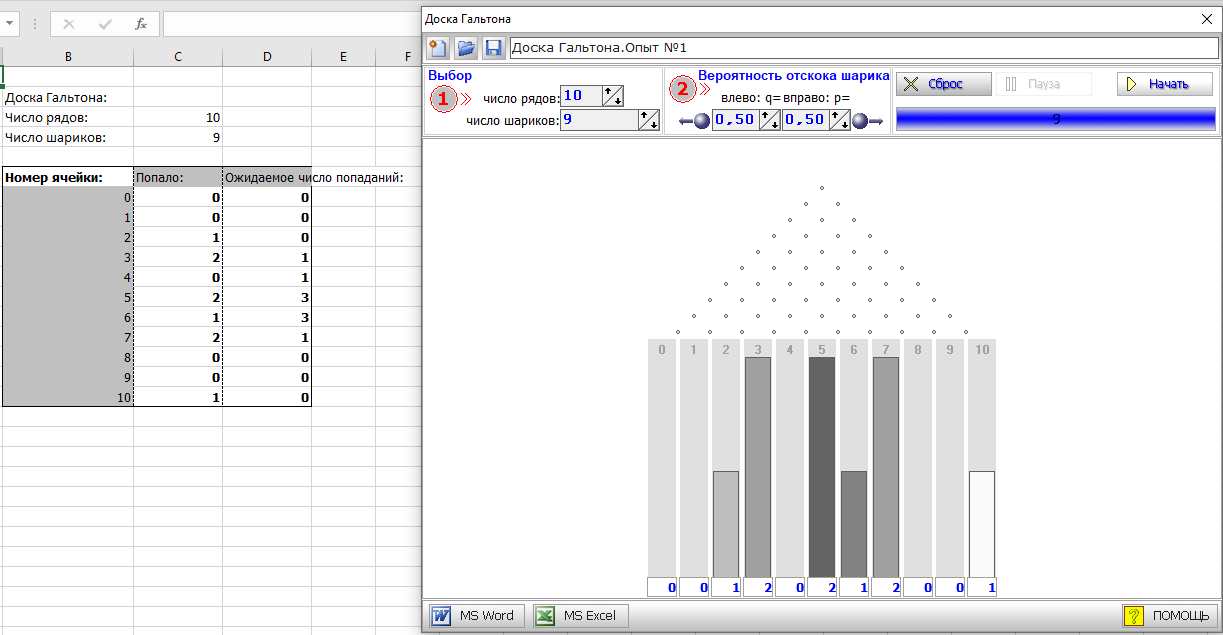
Возьмем 9 шариков (тест Юта - 9 стимулов)
Получаем картинку радикально отличающуюся от колокола нормального распределения. И обратите внимание на отличие количества реально попавших в ячейки шаров от ожидаемого количества. А это отличие и есть то, что называется флуктуациями.
Например, в ячейки 10 имеем стопроцентное отклонение, в ячейке 7 - 50%, в ячейке 6 - 66% и так далее.
При малом количестве стимуов, имеем большую вероятность флуктуаций, которые могут привести к неопределенному и даже ошибочному результату. _________________ http://skl-ol.ru
York, нужна какая то короткая выжимка... Интересно, но не совсем понятно, к чему это?
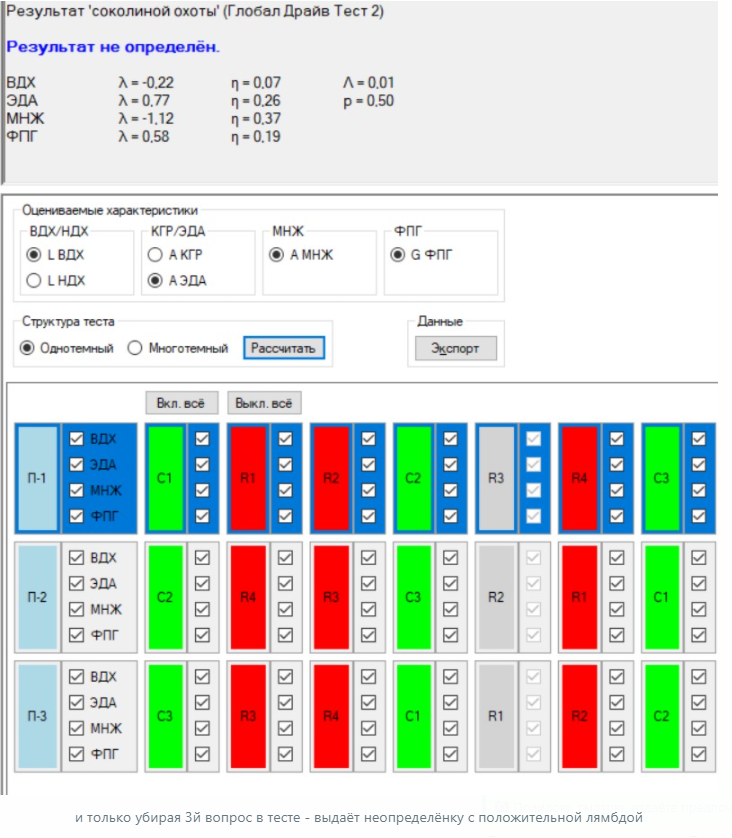
Александр Калафати прислал пример теста когда при исключении трёх вопрос из анализа алгоритм Сокол даёт обвинительный результат. А при включении их, и исключении других выдает неопределенный результат. Такие ситуации могут быть не редки и вызывать у пользователя вопросы и недоверие. Поэтому и решил написать этот пост.
В целом, думаю, надо включить в программу алгоритм поиска флуктуаций с предложеной замены их на медиану. Но конечно надо будет прежде проверить эффект.
Да, но вопрос был не о том , что "смотрите Вааааша , прааааграмма не рааааботает". Я просто указал, на интересный эффект, когда исключение разных вопросов для Сокола даёт разный результат.
Поясню - сейчас в программе СППРП Сокол для теста формата C R1 R2 C R3 R4 C алгоритм Сокол убирает 3й вопрос в ряду. Просто чтобы была возможность обсчитать этот тест. И так получилось, что это единственный вариант, когда алгоритм даёт условно оправдательный вывод. Если убирать 1й, 2й, 4й вопрос в ряду результат будет обвинительный. Вот я и спросил у Юрия почему выбран именно 3й вопрос, а не 4й скажем. _________________ Быть, а не казаться.
http://polygraph-triumph.ru/
Э.э.э... А зачем вообще убирать релевантный вопрос? Ведь если системно убирать релевантный вопрос, то напрочь рушится ядро той структуры теста, которая обкатывалась на получение достоверного результата... _________________ Мое почтение... $erP
................................... ЛЕГКО СОЛГАТЬ ТЯЖЕЛО
Э.э.э... А зачем вообще убирать релевантный вопрос? Ведь если системно убирать релевантный вопрос, то напрочь рушится ядро той структуры теста, которая обкатывалась на получение достоверного результата...
В описаом случае речь идёт о связке теста типа C-R-R-C-R-R-C c алгоритмом Сокол. Требование алгоритма это равное количество C и R. Поэтому один из "лишних" R надо исключать.
По поводу ядра тоже есть вопросы. А что это за ядро такое? Чем ядро C -R - C - R - C - R отличается от ядра C -R -R - C - R - R - C, кроме самой структуры. Как это отличие влияет на точность и почему? Сама структура влияет на точность? Если так, то по какой причине? И влияет ли? _________________ http://skl-ol.ru
Вы не можете начинать темы Вы не можете отвечать на сообщения Вы не можете редактировать свои сообщения Вы не можете удалять свои сообщения Вы не можете голосовать в опросах You cannot attach files in this forum You cannot download files in this forum